Scaling enterprise storage architectures requires a fundamental understanding of distributed system mechanics. Organizations deploy scale out nas Storage to achieve seamless capacity expansion and maintain high performance across growing datasets. Unlike traditional monolithic architectures, this approach links multiple independent nodes into a single clustered system. Each node contributes CPU, memory, and disk resources, theoretically allowing performance to scale linearly as hardware is added.
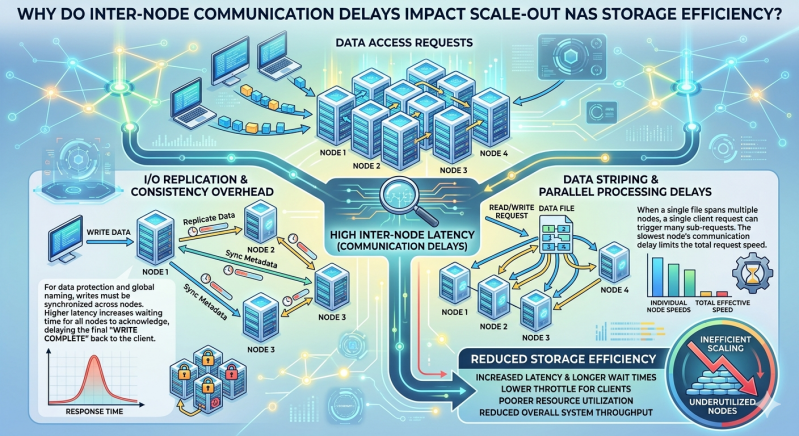
However, achieving this theoretical linear scalability depends heavily on the underlying network infrastructure. The individual nodes must operate cohesively to present a unified file system to clients. This cohesion requires continuous, high-speed data exchanges between the nodes. Every read, write, and metadata update triggers a complex sequence of internal communications designed to keep the cluster synchronized.
When the network connecting these nodes experiences latency, the entire system suffers. Inter-node communication delays directly degrade the aggregate performance of the cluster. Understanding the exact mechanisms behind this degradation is essential for storage architects and systems engineers tasked with optimizing large-scale environments.
The Architecture of Distributed File Systems
To comprehend why delays impact efficiency, one must examine how clustered systems manage data. Traditional Network Attached storage relies on a single controller to manage file access and metadata. In a distributed environment, these responsibilities are shared across the cluster.
Metadata Management and Synchronization
Metadata includes critical file attributes such as permissions, creation dates, and file locations across the physical drives. In scale out nas Storage architectures, metadata is often distributed or replicated across multiple nodes to prevent a single point of failure. When a client requests access to a file, the receiving node must often query other nodes to locate the correct metadata. If the network experiences microsecond delays during these queries, the client experiences a noticeable lag before data transfer even begins.
The Role of Network Attached Storage Protocols
Client-facing protocols, such as NFS (Network File System) and SMB (Server Message Block), require strict consistency. If a client writes data to one node, that update must be immediately visible to clients accessing the cluster through different nodes. The internal protocol used for inter-node communication ensures this consistency through distributed locking mechanisms.
How Inter-Node Communication Mechanisms Function
Nodes in a clustered environment rely on a locking manager to maintain data integrity. When a file is modified, the node handling the request must acquire a write lock. This process necessitates broadcasting messages to other nodes to ensure no conflicting operations are occurring simultaneously.
Distributed Locking and Coherence
Cache coherence protocols ensure that all nodes have the most up-to-date version of a file in their memory. If Node A modifies a file, it must invalidate the cached copies residing on Node B and Node C. This invalidation requires acknowledge signals from the other nodes before Node A can finalize the write operation.
Data Striping and Erasure Coding
Modern scale out nas Storage systems use erasure coding or data striping to protect against hardware failures. A single file is broken into fragments, calculated with parity data, and distributed across several nodes. Writing a single file means sending data chunks over the internal backend network to their respective destinations.
The Root Causes of Communication Delays
Several network variables introduce latency into cluster communications. Understanding these variables helps engineers pinpoint bottlenecks.
Switch Latency and Buffer Exhaustion
The Ethernet or InfiniBand switches connecting the storage nodes are critical infrastructure components. When traffic spikes, switch buffers can fill up, leading to dropped packets and retransmissions. Each retransmission exponentially increases the time required to complete a synchronous storage operation.
Protocol Overhead
The internal communication protocols carry their own overhead. Encapsulating storage commands within TCP/IP packets requires processing power. While features like RDMA (Remote Direct Memory Access) allow nodes to bypass the CPU and write directly to the memory of another node, poorly configured RDMA environments can still introduce severe latency due to congestion control mechanisms.
Impact on Scale Out NAS Storage Efficiency
When inter-node delays occur, they do not simply slow down a single operation. They create a cascading effect that degrades the overall efficiency of the entire Network Attached storage environment.
Latency Amplification
Because clustered storage operations require multiple back-and-forth messages, a small delay on the network is amplified. A one-millisecond delay in network transit can translate to a five-millisecond delay for the client application if the storage operation requires five distinct inter-node communication steps. This amplification is particularly detrimental to transactional workloads that depend on rapid, small-block I/O operations.
Throughput Bottlenecks
Scale out nas Storage is often deployed to handle massive throughput for media rendering, genomic sequencing, or big data analytics. If the nodes cannot exchange parity data and file fragments quickly enough, the internal network becomes a bottleneck. The CPUs on the storage nodes remain idle while waiting for network acknowledgments, effectively wasting the compute resources that were added to increase efficiency.
Resource Starvation
Delayed communications cause locks to be held for longer durations. If Node A takes longer to write a file due to network latency, it holds the write lock for that entire extended period. Other nodes attempting to access the same directory or file must wait in a queue. This resource starvation creates contention, causing overall cluster performance to plummet even when the physical disks have plenty of available IOPS (Input/Output Operations Per Second).
Frequently Asked Questions (FAQ)
What is the ideal network configuration for clustered storage?
Engineers typically recommend a dedicated, non-blocking backend network for inter-node communication, entirely separated from the client-facing frontend network. Utilizing high-bandwidth, low-latency technologies such as 100GbE or 200GbE with RDMA support significantly reduces communication delays.
Can adding more nodes solve performance issues caused by latency?
No. Adding more nodes to a Network Attached storage cluster experiencing high inter-node latency will often exacerbate the problem. More nodes mean more participants in the distributed locking and metadata synchronization processes, which generates heavier internal traffic and increases the probability of delays.
How do administrators measure inter-node latency?
Storage administrators use built-in cluster performance monitoring tools to track backend network latency. Metrics such as lock wait times, internal packet drop rates, and average latency between specific node pairs help identify network infrastructure problems.
Mitigating Latency for Optimal Storage Performance
Maximizing the return on investment for distributed storage infrastructure requires meticulous network engineering. Organizations deploying scale out nas Storage must ensure their backend network fabric is designed specifically for low-latency, lossless data transmission. Implementing technologies like RDMA over Converged Ethernet (RoCE) and enforcing strict Quality of Service (QoS) policies on cluster switches can eliminate the congestion that causes dropped packets.
By prioritizing the health and speed of the internal network, systems engineers can prevent latency amplification and resource starvation. This systematic approach guarantees that the Network Attached storage cluster delivers the linear scalability and high performance necessary to support modern, data-intensive enterprise workloads.
Add comment
Comments