Network Attached Storage architectures rely heavily on caching mechanisms to deliver low-latency data access to client nodes. By keeping frequently accessed data in local memory, a NAS System reduces round-trip times to the physical disks. However, maintaining cache coherence across distributed nodes introduces significant overhead. When multiple clients attempt to modify the same shared dataset simultaneously, the storage controller must revoke the cached copies across the network.
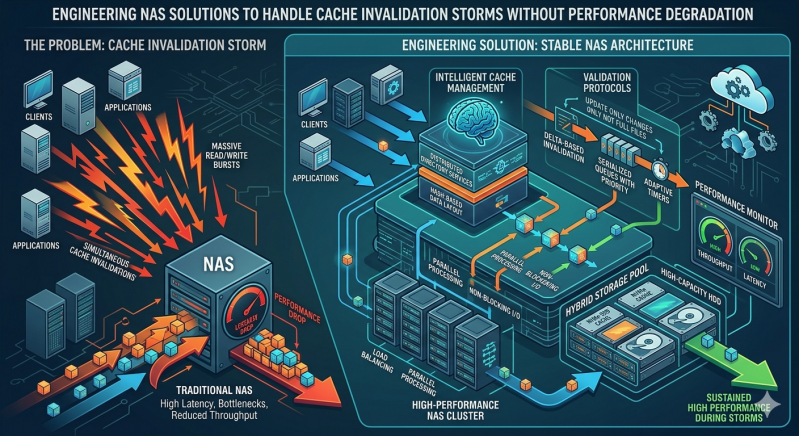
This revocation process can quickly spiral out of control. A cache invalidation storm occurs when an overwhelming number of invalidation requests saturate the network and exhaust CPU cycles on the storage controllers. The result is a severe degradation in overall storage performance, often bringing critical business applications to a complete halt.
Engineers must design NAS solutions capable of handling these intense metadata spikes without compromising throughput or increasing latency. This requires a systematic approach to coherence protocols, lock management, and network topology. By implementing advanced architectural strategies, organizations can maintain high-speed data access even during massive cache invalidation events. The following sections outline the engineering methodologies required to stabilize your NAS System under heavy concurrent workloads.
The Anatomy of a Cache Invalidation Storm
To engineer robust storage architectures, you must first understand the mechanics of cache coherence. Most distributed file systems utilize a write-invalidate protocol. When one node modifies a file, the storage controller sends an invalidation message to every other client holding that data in their local cache.
In steady-state operations, this process functions efficiently. A cache invalidation storm develops during specific, highly concurrent events. For instance, massive batch processing jobs, hypervisor migrations, or large-scale data ingestion can trigger millions of invalidation messages per second. The storage controllers must process acknowledgments from every node before committing the write, creating a severe bottleneck. The processing queue fills up rapidly, causing a cascading failure that drops system IOPS significantly.
Architectural Strategies for Stable NAS Solutions
Mitigating these storms requires shifting away from basic broadcast-based invalidation toward more intelligent, scalable protocols. Engineers must implement targeted approaches to manage cache coherence.
Directory-Based Coherence Protocols
Traditional broadcast protocols spam the entire network with invalidation requests. Directory-based coherence solves this by maintaining a centralized directory that tracks exactly which client holds which blocks of data. When a modification occurs, the NAS System only sends invalidation messages to the specific nodes caching that exact block. This targeted approach drastically reduces network traffic and CPU load on the storage controller, preventing a localized write-heavy workload from escalating into a full-scale storage storm.
Lease-Based Cache Management
Another highly effective method for optimizing NAS solutions is the implementation of lease-based cache mechanisms. Instead of granting indefinite cache validity that requires explicit invalidation, the storage controller grants a time-bound lease. Once the lease expires, the client must request a renewal or drop the data from its cache. During high-contention periods, the controller can dynamically shorten lease times or refuse renewals, effectively clearing the cache without generating a flood of invalidation packets.
Safeguarding the NAS Backup Repository
Backup and disaster recovery operations are frequent culprits of cache invalidation storms. When an enterprise initiates a full synthetic backup or a large snapshot consolidation, the software must traverse and read massive amounts of metadata and file blocks. If this data is actively being modified by production workloads, the resulting conflict generates endless invalidations.
To prevent backups from degrading production performance, engineers must carefully architect the NAS Backup Repository. This dedicated tier should operate asynchronously from the primary cache layer. Utilizing redirect-on-write (ROW) snapshot technology allows the NAS Backup Repository to lock point-in-time data without engaging the primary cache coherence protocol.
Furthermore, isolating the network traffic for the NAS Backup Repository ensures that backup-induced metadata operations do not compete with production data paths. Implementing precise Quality of Service (QoS) rules at the controller level can restrict the cache invalidation rate originating from backup tasks, ensuring the primary NAS System remains responsive to client requests.
Scaling Your NAS System for High Availability
Hardware design plays an equally important role in surviving invalidation storms. A well-engineered NAS System utilizes separated control and data planes. By decoupling metadata processing from actual data read and write operations, the storage node can allocate dedicated CPU threads and memory strictly for coherence management.
Modern NAS solutions often incorporate non-volatile memory express (NVMe) caching layers and remote direct memory access (RDMA) capabilities. RDMA allows the storage controller to bypass the client CPU entirely and write invalidation markers directly into the client's memory space. This drastically reduces the latency of coherence checks and prevents client-side CPU bottlenecks from stalling the entire storage cluster.
Organizations must also monitor their NAS Backup Repository for metadata bottlenecks. Using dedicated flash storage specifically for metadata databases ensures that even if an invalidation storm begins to form, the system can process the requests fast enough to prevent a massive queue pileup.
Designing Resilient Storage Infrastructures
Designing a storage architecture that withstands extreme concurrent workloads requires precision engineering and a deep understanding of distributed systems. Cache invalidation storms represent a fundamental challenge in computer science, but they can be mitigated through targeted coherence protocols, dynamic leases, and hardware-accelerated metadata processing.
To ensure your infrastructure remains highly available, audit your current caching mechanisms and monitor metadata latency during peak workloads. By upgrading to advanced NAS solutions, isolating your NAS Backup Repository, and fine-tuning your coherence parameters, you can eliminate performance degradation and maintain a highly responsive NAS System. Evaluate your current storage architecture today to identify potential coherence bottlenecks before they impact your critical operations.
Add comment
Comments