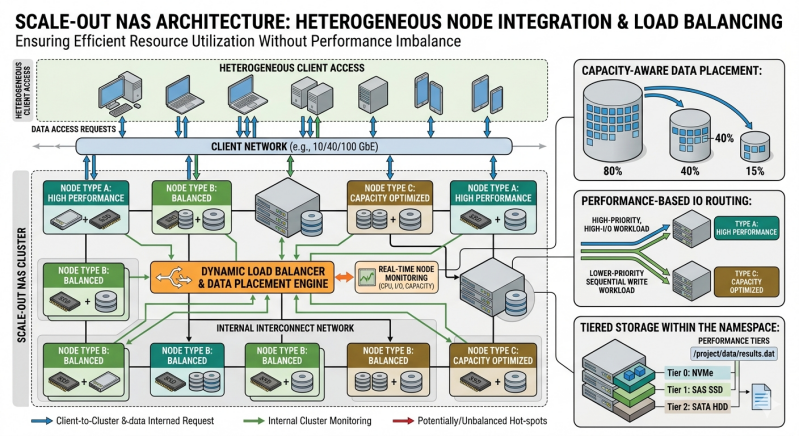
Scaling storage infrastructure requires adding hardware resources to an existing cluster. When organizations expand their capacity, they rarely purchase the exact same hardware generations used in the initial deployment. This results in node heterogeneity, a scenario where a single storage cluster contains servers with different CPU architectures, memory capacities, and storage media types.
While adding newer, faster nodes increases the total theoretical performance of the cluster, it introduces a significant engineering challenge. Distributed file systems typically distribute data and client requests evenly across all available nodes. If a system assigns an equal workload to a three-year-old node and a brand-new NVMe-powered node, the older hardware becomes a bottleneck. This creates a severe performance imbalance that degrades the overall throughput and latency of the entire system.
Addressing this imbalance requires a sophisticated approach to system architecture. Administrators and storage engineers must implement logical frameworks that account for varying hardware capabilities. By designing an intelligent Scale out nas Storage environment, organizations can efficiently handle node heterogeneity, ensuring that newer hardware maximizes its potential without overwhelming older infrastructure.
Understanding the Mechanics of Performance Imbalance
In a homogeneous environment, predictable performance relies on uniform hardware processing data at the exact same rate. When heterogeneity is introduced into NAS Storage, this predictable baseline shatters. File systems utilizing standard algorithmic distribution, such as static hashing, blindly send data to nodes based on mathematical formulas rather than real-time hardware capabilities.
This blind distribution causes several distinct operational issues. Older nodes struggle to process high volumes of Input/Output Operations Per Second (IOPS), leading to increased queue depths. As these queues grow, latency spikes. Since distributed storage operations often require acknowledgment from multiple nodes before confirming a write operation to the client, a single slow node forces the entire cluster to wait.
Furthermore, network interfaces often differ between hardware generations. Mixing 10GbE nodes with 100GbE nodes creates flow control issues. The faster nodes overwhelm the slower ones during internal replication or rebalancing operations. Solving this requires moving away from static data distribution and adopting dynamic, hardware-aware management protocols.
Architectural Strategies for Scale-Out NAS Storage
Designing a robust system requires implementing mechanisms that constantly evaluate node performance and distribute workloads accordingly. This shifts the operational paradigm from equal distribution to equitable distribution, where nodes receive workloads proportional to their real-time computing and storage capabilities.
Implementing Dynamic Data Placement
The most effective method for handling mismatched hardware in Scale out nas Storage is dynamic data placement. Instead of relying on rigid hashing algorithms, the file system actively monitors the performance metrics of each node. These metrics include CPU utilization, disk latency, and network bandwidth saturation.
When a client initiates a write operation, the storage software evaluates the current health and capacity of the cluster. It then directs the heaviest workloads to the nodes with the lowest latency and highest available throughput. If an older node begins to show signs of bottlenecking, the system automatically redirects new I/O requests to newer, more capable nodes. This ensures that high-performance hardware is fully utilized while preventing legacy nodes from causing cluster-wide latency.
Utilizing Tiered Storage Architectures
Another highly effective approach involves logical tiering within the NAS Storage environment. Engineers can configure the file system to recognize the specific media types housed within different nodes. For example, a cluster might contain a mix of NVMe SSDs, SATA SSDs, and high-capacity HDDs.
By grouping these resources into distinct performance tiers, the system can enforce data placement policies based on workload requirements. Metadata and frequently accessed hot data are pinned strictly to the NVMe nodes. As data ages and becomes cold, background processes migrate it to the older, slower HDD nodes. This prevents the system from accidentally placing high-demand databases on legacy hardware, thereby eliminating a major source of performance imbalance.
Intelligent Metadata Management
Metadata operations often account for more than fifty percent of all file system requests. Directory lookups, permission checks, and file attribute modifications require massive amounts of small, random IOPS. If a Scale out nas Storage cluster distributes metadata evenly across heterogeneous nodes, the slower nodes will choke under the transactional weight.
To prevent this, architects isolate metadata management. The system designates the fastest, most capable nodes to act as metadata servers. By processing all directory structures and file mappings on the newest hardware, the system accelerates the most critical aspect of file retrieval. The older nodes are then relegated strictly to storing large, sequential data payloads, a task they can handle with acceptable latency.
Maintaining Long-Term Cluster Stability
Hardware lifecycles dictate that node heterogeneity is a permanent state for any growing enterprise environment. A storage architecture must adapt continuously as components are added, retired, or repurposed.
Administrators must deploy comprehensive telemetry and monitoring tools that provide granular visibility into individual node performance. By establishing baseline metrics for each hardware generation, engineering teams can set automated alerts for performance degradation. If a legacy node consistently fails to meet its assigned IOPS threshold, the Scale out nas Storage software can automatically drain its active connections and mark it for maintenance or decommissioning.
Additionally, weight-based load balancing algorithms should be fine-tuned regularly. By manually assigning performance weights to different nodes based on their benchmarked capabilities, administrators guide the automated distribution logic. A node with a weight of 1.5 will receive fifty percent more traffic than a baseline node with a weight of 1.0. This systematic calibration ensures that performance imbalance remains completely mitigated.
Optimizing Your Storage Infrastructure for Continuous Growth
Efficiently managing node heterogeneity prevents hardware mismatches from paralyzing enterprise operations. By abandoning static distribution and embracing hardware-aware data placement, logical tiering, and isolated metadata management, engineers can build highly resilient clusters. These strategies ensure that every piece of hardware, regardless of its age, contributes positively to the total throughput of the system.
Implementing these precise architectural controls allows organizations to expand their NAS Storage environments confidently. When the underlying file system dynamically adapts to the physical hardware, scaling out becomes a seamless, risk-free process that consistently delivers maximum performance.
Add comment
Comments