Enterprise environments generate data at unprecedented rates, creating highly complex storage ecosystems. Within these environments, administrators frequently encounter non-uniform file size distributions. This scenario occurs when an infrastructure must simultaneously manage billions of tiny files—such as application logs, IoT telemetry, or financial transaction records—alongside massive, multi-gigabyte files like 4K video assets, genomic sequencing data, or virtual machine images.
Traditional storage architectures often struggle under the weight of this dichotomy. A system tuned exclusively for high throughput to support large files will generally choke on the massive metadata overhead generated by small files. Conversely, a system optimized for high IOPS to handle small files might lack the bandwidth necessary for large data streams. Resolving this tension requires a fundamental rethinking of how we deploy and configure enterprise storage systems.
This article explores the technical methodologies required to design advanced NAS storage solutions capable of handling extreme variations in file sizes. By examining metadata architecture, automated tiering, and hybrid system design, IT architects can build resilient Network Attached storage frameworks that maintain high performance across all data types, regardless of scale.
Understanding Non-Uniform File Distributions
To engineer effective NAS storage solutions, it is crucial to understand exactly why non-uniform data environments cause performance degradation. The root cause usually lies within the file system architecture and the physical limitations of the underlying storage media.
The Small File Problem and Metadata Overhead
Small files inflict severe penalties on storage performance, primarily due to metadata overhead. Every file on a storage volume requires an inode (or equivalent metadata structure) that records its permissions, creation date, physical location on the disk, and other attributes. When an application attempts to read one million tiny text files, the system must perform one million metadata lookups before any actual payload data is retrieved.
In standard Network Attached storage configurations, these metadata operations require random read/write actions. If the storage array utilizes spinning disk drives (HDDs), the physical seek time of the read/write heads creates massive latency bottlenecks. Furthermore, an abundance of small files can lead to inode exhaustion, a state where the file system runs out of available metadata entries even if physical storage capacity remains available.
The Large File Challenge and Throughput Bottlenecks
Large files present the opposite challenge. A massive uncompressed video file does not stress the metadata architecture; it requires sustained sequential throughput. If the network interface or the storage controller lacks the necessary bandwidth, read and write operations will stall.
When a Network Attached storage system attempts to serve massive sequential read requests simultaneously with millions of random metadata lookups, the controller becomes heavily congested. This resource contention results in high latency for the small files and degraded throughput for the large files, effectively crippling the entire workflow.
Architectural Strategies for Network Attached storage
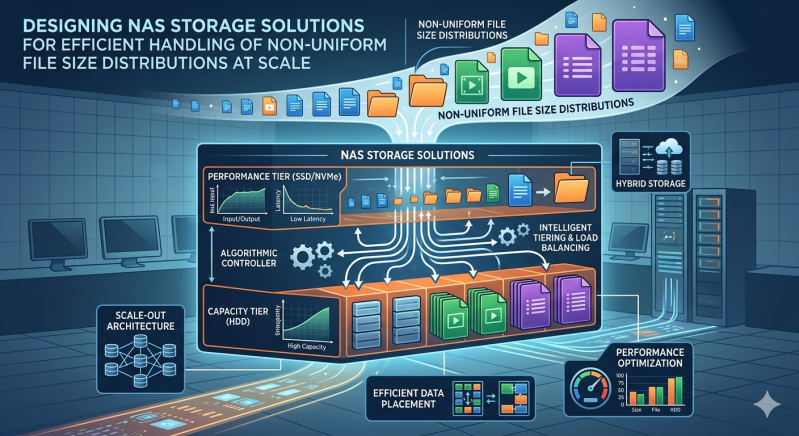
Designing storage that handles both extremes requires a multi-layered architectural approach. Advanced NAS storage solutions utilize intelligent software layers combined with specialized hardware to route data to the most appropriate storage medium dynamically.
Implementing Automated Storage Tiering
Automated storage tiering is a critical component for managing non-uniform data sets. This technology analyzes data access patterns and file types in real-time, automatically migrating data between different classes of storage media without user intervention.
For instance, an advanced Network Attached storage array can be configured with a tier of NVMe solid-state drives (SSDs) and a massive backend tier of high-capacity HDDs. The system's intelligent caching algorithms route all incoming small files and metadata updates directly to the NVMe tier. The flash memory absorbs the punishing random IOPS workload flawlessly. Meanwhile, large sequential files can be written directly to the HDD tier, which provides cost-effective, high-bandwidth sequential storage. As small files age and become cold, the tiering software transparently moves them to the HDD tier, freeing up premium NVMe space.
Variable Block Sizing and File System Optimization
The underlying file system dictates how data is physically written to the disks. Many legacy file systems use fixed block sizes. If a system uses a large block size (e.g., 128KB) to optimize for large files, writing a 4KB file will still consume an entire 128KB block, resulting in massive wasted capacity.
Modern NAS storage solutions employ variable block sizing. The file system dynamically allocates block sizes based on the incoming file size. Small files are packed efficiently into small blocks, eliminating wasted space, while large files are striped across wide blocks to maximize sequential read and write speeds. Furthermore, advanced file systems utilize distributed metadata architectures, spreading the metadata processing load across multiple nodes in a clustered environment to prevent any single controller from becoming a bottleneck.
Hybridizing NAS Storage Solutions with Object Storage
As data volumes scale into the petabyte range, strictly relying on a traditional POSIX-compliant file system becomes economically and technically unfeasible. To mitigate this, enterprise architects are increasingly blending Network Attached storage protocols with object storage backends.
Object storage flattens the file system hierarchy. Instead of a deep, complex tree of directories and inodes, data is stored as discrete objects within a flat namespace, identified by unique cryptographic hashes. This architecture scales infinitely and handles metadata with extreme efficiency. By fronting an object storage cluster with a high-performance NAS gateway, organizations get the best of both worlds.
The gateway provides standard NFS or SMB protocols for application compatibility, while the object backend effortlessly handles the non-uniform file distribution. Small files are batched and written as larger objects, neutralizing the metadata penalty, while large files are stripped across multiple object storage nodes for maximum throughput.
Frequently Asked Questions
Why do small files degrade Network Attached storage performance?
Small files require a disproportionate amount of metadata processing. For every small file written or read, the storage controller must process its attributes, location, and permissions. When dealing with millions of files, this metadata overhead causes random I/O bottlenecks, especially on systems utilizing spinning hard drives.
How do modern NAS storage solutions handle metadata bottlenecks?
Advanced systems separate metadata processing from data payload processing. They often store the file system's metadata directory on dedicated, high-speed NVMe flash drives. This allows the system to execute rapid metadata lookups and directory traversals without impacting the throughput of the main storage pool.
Can object storage replace Network Attached storage entirely?
While object storage is highly scalable, it does not support the low-latency, file-locking, and POSIX-compliant operations required by many legacy enterprise applications. Therefore, most organizations use a hybrid approach, utilizing NAS gateways to bridge standard applications with highly scalable object storage backends.
Future-Proofing Your Storage Architecture
Designing infrastructure to accommodate non-uniform file size distributions requires a departure from legacy, monolithic storage arrays. By implementing intelligent tiering, variable block sizing, and flash-accelerated metadata management, IT leaders can construct resilient storage ecosystems capable of handling any data profile.
To begin optimizing your environment, initiate a comprehensive data profiling audit. Utilize infrastructure monitoring tools to analyze your current file size distributions, identify your metadata bottlenecks, and map your IOPS-to-throughput ratios. This telemetry will provide the empirical data necessary to architect robust NAS storage solutions that will sustain your organizational demands well into the future.
Add comment
Comments