Managing massive datasets introduces complex structural challenges for IT infrastructure. When an organization scales its data lakes to billions of files, the sheer volume of metadata—data about the data, such as permissions, creation dates, and file locations—can overwhelm traditional storage architectures. Every read, write, and file modification requires a metadata operation. When millions of these operations occur simultaneously, systems experience severe bottlenecks known as metadata contention.
This contention leads to high latency, slower application performance, and systemic inefficiencies. Administrators often find that the storage hardware itself has plenty of capacity and bandwidth, but the underlying file system cannot process the metadata requests fast enough. Overcoming this requires advanced architectural strategies that distribute the computational load across the entire storage cluster.
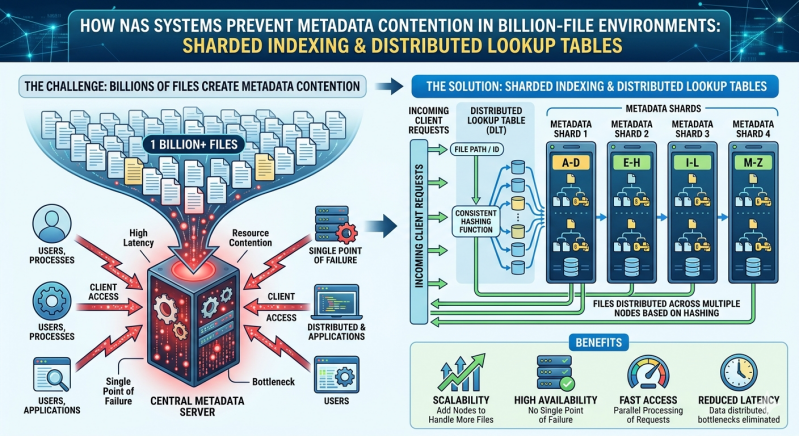
Modern NAS Systems address this bottleneck by moving away from centralized metadata servers. Instead, they rely on distributed architectures utilizing sharded indexing and distributed lookup tables. These technologies allow Scale out storage environments to process millions of metadata operations per second without locking up resources. By decentralizing how metadata is tracked and retrieved, IT teams can maintain high performance even as file counts push into the billions.
The Mechanics of Metadata Contention
To understand the solution, one must examine the root cause of the problem. In legacy file systems, metadata is often stored in a monolithic database or a centralized directory tree. When a user or application requests access to a file, the system must query this central repository.
As the file count grows, the directory tree becomes massive. Simultaneous requests from thousands of clients force the central metadata server to lock certain directories to maintain consistency during updates. This locking mechanism creates a queue. While one file is being updated, other operations waiting for access to the same directory path are stalled. This is metadata contention.
In high-performance computing, genomic sequencing, or large-scale media rendering, applications generate millions of small files rapidly. A centralized metadata architecture simply cannot handle the concurrency required. Enterprise nas Storage solutions must employ a different mathematical approach to track data locations across multiple nodes seamlessly.
Sharded Indexing in Modern NAS Systems
Sharded indexing provides a highly effective method for eliminating centralized bottlenecks. Rather than keeping all metadata in a single, massive index, the system fragments—or "shards"—the index into smaller, manageable pieces. Each shard is then assigned to a different storage node within the cluster.
When a file is created, a mathematical hashing algorithm processes the file name or identifier. The output of this algorithm determines exactly which shard will hold the metadata for that specific file. Because the hashing algorithm distributes files evenly across all available shards, no single node takes on a disproportionate amount of the metadata workload.
This approach transforms how NAS Systems handle concurrency. If ten thousand files are written simultaneously, the hashing algorithm distributes the metadata updates across dozens or hundreds of nodes. Directory locking is restricted only to the specific shard handling a particular file, leaving the rest of the system free to process other requests.
Furthermore, as the organization adds more hardware to the cluster, the indexing structure automatically rebalances. The Scale out storage architecture redistributes the shards across the new nodes, ensuring that metadata processing power grows linearly alongside physical storage capacity.
Distributed Lookup Tables
While sharded indexing dictates where metadata lives, distributed lookup tables determine how nodes communicate to find that metadata quickly. A distributed lookup table, often implemented as a Distributed Hash Table (DHT), acts as the routing mechanism for the storage cluster.
When a client requests a file, the receiving node consults the distributed lookup table. The table uses the same hashing algorithm used during file creation to instantly calculate which node holds the relevant metadata shard. The request is then forwarded directly to the correct node via the backend network.
This peer-to-peer routing eliminates the need for a central metadata controller. Every node in the Scale out storage environment holds a copy of the lookup table. Therefore, any node can receive a client request and instantly know where the data resides. This creates a highly resilient system. If a node fails, the distributed lookup table updates, and redundant copies of the metadata shards are automatically promoted to active status on surviving nodes.
Scaling Performance with Enterprise Architectures
Implementing sharded indexing and DHTs requires robust hardware and sophisticated software orchestration. Enterprise nas Storage platforms utilize non-volatile memory express (NVMe) drives and high-speed remote direct memory access (RDMA) networking to minimize the physical latency of metadata lookups.
When a distributed lookup table points a request to a specific node, the NVMe drives retrieve the metadata shard in microseconds. The RDMA network allows nodes to read this metadata directly from each other's memory spaces, bypassing the traditional CPU overhead associated with network communication.
This combination of distributed software architecture and high-performance hardware guarantees that metadata operations do not impede file read and write speeds. Organizations can confidently deploy billion-file workloads knowing their infrastructure will not suffer from directory lockups or server bottlenecks.
Expanding Capabilities in Enterprise NAS Storage
The transition to decentralized metadata management unlocks new capabilities for data-intensive industries. Artificial intelligence and machine learning pipelines, for instance, require continuous ingestion of massive datasets. Centralized systems frequently choke on these workloads, starving the GPU clusters of data.
By leveraging sharded indexing, NAS Systems keep the AI pipelines fed. The distributed architecture allows data scientists to run complex analytical queries across billions of files simultaneously. The metadata for these files is retrieved in parallel from across the entire cluster, drastically reducing the time required to complete training epochs.
Additionally, this architecture simplifies data lifecycle management. When administrators need to archive old files or replicate data to a disaster recovery site, the distributed system can scan the metadata shards in parallel. Tasks that would take weeks on a centralized file system can be completed in hours using a highly parallelized Scale out storage approach.
Optimizing for the Future of Data
Managing billion-file environments requires a fundamental shift in how file systems process background operations. Relying on centralized metadata servers guarantees performance degradation as capacities grow. By implementing sharded indexing and distributed lookup tables, modern NAS Systems eliminate the primary causes of metadata contention.
This mathematical, decentralized approach ensures that metadata operations are distributed evenly across all available hardware. Organizations utilizing modern Enterprise nas Storage can therefore scale their infrastructure without fear of bottlenecks, ensuring high performance and continuous availability for their most demanding, data-intensive applications.
Add comment
Comments