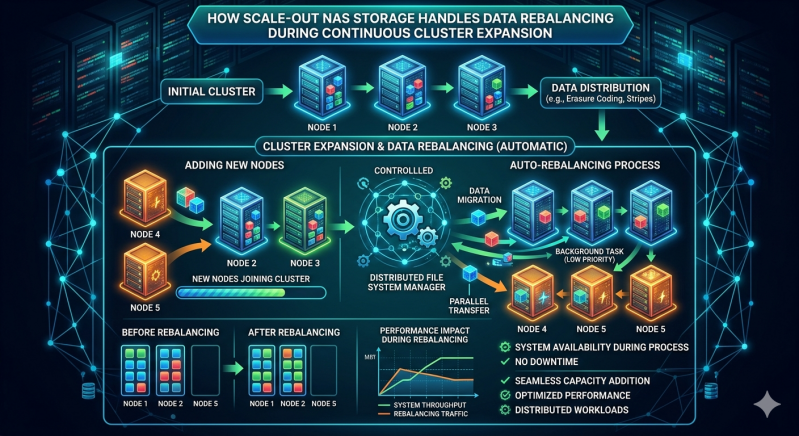
As enterprise data footprints grow, storage administrators frequently rely on distributed architectures to maintain performance and capacity. Adding new nodes to an existing cluster introduces a critical operational challenge. The system must ensure that data is distributed evenly across all available hardware. Without a systematic redistribution process, new nodes remain underutilized while older nodes suffer from input/output bottlenecks and capacity exhaustion.
To solve this hardware imbalance, modern storage frameworks employ continuous data rebalancing. This background operation detects newly provisioned capacity and migrates existing files, objects, or blocks to the new hardware. The process must happen seamlessly, preventing disruption to active client connections and critical workloads. This allows organizations to expand their storage footprint without scheduling extensive downtime.
Understanding the exact mechanisms behind this redistribution helps engineers optimize their infrastructure. This article explains how Scale out NAS Storage handles data rebalancing during continuous cluster expansion, detailing the algorithms, resource management techniques, and architectural designs that make non-disruptive scaling possible.
The Core Architecture of Distributed Storage
Unlike traditional monolithic arrays, Scale out NAS Storage utilizes a distributed file system spanning multiple independent nodes. Each node contributes processing power, memory, and disk capacity to a single, unified storage pool. When an administrator adds a new node, the total cluster capacity increases linearly.
However, the distributed file system must integrate this new raw capacity into the logical namespace. Modern NAS Systems handle this integration through a centralized or distributed metadata management layer. The metadata tracks the physical location of every file across the cluster. When a new node comes online, the metadata layer acknowledges the additional capacity and triggers the rebalancing protocol. The system calculates the current capacity skew and determines the optimal data layout required to achieve equilibrium.
Mechanisms of Data Redistribution
Redistributing data across NAS Systems requires sophisticated algorithms to determine which files move and where they go. Most Scale out NAS Storage environments utilize either hash-based distribution or dynamic capacity-based allocation to manage this logic.
Hash-Based Distribution
In hash-based NAS Systems, an algorithm calculates a mathematical hash based on the file name or object identifier. This hash dictates the file's physical location on a specific node. When a cluster expands, the hash space increases. The system recalculates the hashes, identifying which existing files now belong on the newly added node. The system then initiates a background transfer for those specific files. This deterministic approach ensures data spreads evenly based on mathematical probability.
Dynamic Capacity-Based Allocation
Other NAS Systems utilize a capacity-driven approach. The cluster management software monitors the utilization percentages of all nodes. If legacy nodes operate at 85 percent capacity while a new node sits empty, the system flags a severe capacity imbalance. The rebalancing engine selects files from the heavily utilized nodes and migrates them to the new hardware. This process continues until all nodes reach a roughly equivalent utilization metric.
Managing Input/Output and Traffic Throttling
Moving terabytes of data between nodes consumes significant network bandwidth and processing power. If left unmanaged, the rebalancing operation could severely degrade read and write performance for frontend users. Scale out NAS Storage addresses this challenge through intelligent resource throttling and traffic prioritization.
Prioritizing Frontend Traffic
Storage operating systems assign lower priority to background migration tasks compared to active client traffic. If a database application requests a file, the system allocates CPU cycles and disk access to serve that request immediately. The rebalancing process only utilizes idle resources. This guarantees that critical business operations experience minimal latency variations during a cluster expansion event.
Dynamic Rate Limiting
Administrators can frequently configure rebalancing policies within their NAS Systems. During peak business hours, the system might throttle data migration to a minimal transfer rate, such as 50 megabytes per second. During off-peak hours or weekends, the system can automatically increase this limit. This allows the cluster to utilize the full backend network fabric to complete the migration quickly without disrupting daily operations.
The Role of Backend Networking
The physical network topology plays a crucial role in how efficiently a cluster can rebalance its data. Enterprise Scale out NAS Storage deployments separate frontend client traffic from backend node-to-node traffic.
Frontend traffic travels over standard Ethernet networks directly to the client machines. Backend traffic, including data rebalancing operations, utilizes a dedicated, high-speed network fabric. By isolating the rebalancing traffic on a dedicated backend switch, the storage cluster in NAS systems prevents data migration tasks from congesting the network used by active applications.
Handling Metadata Updates and Client Access
While a file moves from an old node to a new node, clients might attempt to read or modify it. Scale out NAS Storage maintains strict consistency protocols to handle these concurrent access requests. Data integrity remains the highest priority throughout the entire operation.
When migration begins, the file system places a temporary lock on the file. If a client requests read access, the system serves the data from the original node. If a client requests write access, the system typically pauses the migration, allows the write to complete on the original node, and then restarts the transfer. Once the file fully transfers to the new node, the system updates the central metadata registry. Future client requests automatically route to the new physical location without the client ever knowing the data moved.
Sustaining Optimal Storage Performance
Continuous cluster expansion represents a fundamental requirement for modern data centers. To leverage the full financial and operational benefits of distributed hardware, organizations must rely on automated data mobility. By understanding how the underlying file system manages metadata, throttles background traffic, and executes migration algorithms, administrators can confidently scale their infrastructure. Ultimately, efficient data rebalancing ensures that every added node immediately contributes to the overall speed, reliability, and capacity of the enterprise storage environment.
Add comment
Comments