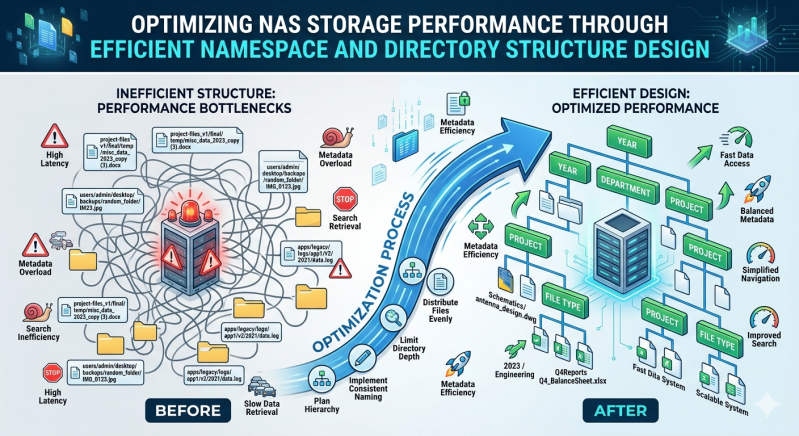
Network-attached storage systems often face performance bottlenecks not from raw disk throughput, but from inefficient metadata handling. As file counts grow into the billions, the overhead required to manage file attributes, permissions, and directory locations can overwhelm the storage controller. This creates excessive latency during read and write operations, directly impacting application performance and user productivity.
The foundation of high-performance file serving lies in the logical organization of data. Efficient namespace architecture and systematic directory structure design mitigate the load on metadata processing units. By organizing data in a way that aligns with the underlying file system's capabilities, storage administrators can significantly reduce directory traversal times and lock contention.
Implementing these architectural principles ensures that organizations extract maximum input/output operations per second (IOPS) from their infrastructure. This guide details the technical strategies required to structure namespaces and directories effectively, ensuring predictable and scalable performance across modern storage environments.
The Role of Namespace Architecture in Storage Performance
A namespace serves as the logical overlay that maps user-facing file paths to physical data blocks. When applications request access to a file, the storage controller must parse the namespace to locate the corresponding inode or metadata object. If the namespace is poorly designed, this lookup process generates excessive disk operations.
In a standard NAS Storage deployment, a global namespace federates data access across multiple physical volumes or nodes. This abstraction simplifies client access but requires rigorous management to prevent metadata hotspots. A highly fragmented or overly complex namespace forces the system to execute multiple remote procedure calls (RPCs) just to resolve a single file path.
To optimize this process, storage architects must deploy namespaces that logically group related datasets while maintaining strict boundaries between disparate workloads. For instance, isolating transactional application data from static archival data within the namespace prevents intensive metadata queries on the archive from impacting the latency of transactional workloads. Implementing a structured, predictable namespace is a fundamental requirement for maximizing the throughput of any Enterprise NAS Storage system.
Designing Efficient Directory Structures
The physical layout of files within directories directly dictates metadata performance. A common architectural flaw is the "fat directory" problem, where millions of files reside within a single directory level. When a client attempts to list the contents of a fat directory, or when a new file is written to it, the storage system must lock the directory's metadata block. This serialization causes severe queueing delays.
To prevent directory-level locking, administrators must implement directory sharding. Sharding involves distributing files across a nested hierarchy of subdirectories. A common methodology uses hashing or date-based naming conventions to automatically sort incoming files into manageable groupings. For example, a system storing image files might use the first two characters of a file's hash to determine its top-level directory, and the next two characters for the subdirectory.
However, directory depth must also be carefully managed. While shallow directories cause lock contention, directories that are too deep require the system to parse excessive path components. Every level of a directory tree requires a separate metadata lookup. The optimal balance typically involves maintaining no more than 10,000 to 50,000 files per directory and restricting tree depth to four or five levels.
Proper directory sizing profoundly impacts caching efficiency. Modern NAS Storage controllers cache directory metadata in random-access memory (RAM). Keeping directory sizes constrained ensures that frequently accessed directories fit entirely within the controller's cache, yielding near-instantaneous lookups and reducing backend disk operations.
Mitigating Hotspots in Distributed Environments
Traditional monolithic storage systems manage metadata centrally, but modern architectures distribute data and processing power across multiple discrete hardware nodes. In a Scale out storage cluster, the directory structure dictates how metadata workloads are distributed across the available nodes.
If an organization utilizes a deeply unbalanced directory structure, a single node may end up hosting the metadata for the most heavily accessed directory. This creates a severe performance bottleneck, as the overloaded node struggles to process requests while the remaining nodes sit idle. Proper namespace segmentation allows a Scale out storage system to distribute metadata processing evenly across the entire cluster.
Administrators must align their directory hierarchy with the specific hashing algorithm utilized by their Scale out storage platform. Some file systems distribute metadata based on directory boundaries, meaning that creating multiple distinct top-level directories forces the system to allocate the workload across different physical nodes. This careful alignment maximizes the aggregate processing capability of the entire Enterprise NAS Storage cluster, ensuring linear performance scaling as new hardware is added.
Advanced Tuning and Metadata Management
Beyond basic directory layouts, several advanced tuning parameters govern storage performance. The nature of the application workload—whether it generates highly sequential read patterns or heavily randomized write patterns—must dictate the namespace design.
Applications that perform heavy file creation and deletion cycles generate massive metadata churn. Isolating these volatile workloads into dedicated directories prevents their associated metadata fragmentation from degrading the performance of stable datasets. Furthermore, adjusting attribute cache timeouts on the client side can reduce the frequency of metadata requests sent to the storage cluster. By allowing the client to cache file permissions and attributes locally for a few extra seconds, the overall network burden decreases significantly.
Symbolic links should be used sparingly within high-performance environments. Every time a client traverses a symbolic link, the storage controller must perform an additional lookup to resolve the final target path. In a massive Enterprise NAS Storage deployment, these accumulated traversal latencies compound into noticeable application delays.
Regular auditing of the directory tree is critical. As environments grow, automated reporting tools must scan for directory structures that are approaching locking thresholds. Proactively restructuring these directories ensures that the Scale out storage infrastructure remains performant as capacity scales into the petabyte range.
Sustaining Performance Through Architectural Discipline
High-performance data access relies entirely on the logical organization of files and directories. Without a systematic approach to metadata management, even the most capable hardware will ultimately succumb to queueing delays and lock contention.
Optimizing directory depth, implementing intelligent sharding, and balancing workloads across nodes are non-negotiable requirements for massive data environments. Because NAS Storage performance is so closely tied to these logical constructs, continuous architectural discipline is required.
Ultimately, Enterprise NAS Storage demands rigorous design upfront to prevent systemic degradation over time. By pairing highly optimized namespaces with a robust Scale out storage architecture, organizations can maintain low latency and high throughput, regardless of how large their file systems grow. Maintaining these best practices guarantees that the NAS Storage infrastructure remains an asset to operational velocity rather than a bottleneck.
Add comment
Comments