Maintaining data consistency across multiple distributed nodes is a fundamental engineering challenge in modern storage architecture. As enterprise environments generate massive volumes of unstructured data, traditional monolithic storage arrays fail to provide the necessary flexibility and performance. This limitation has driven the widespread adoption of Scale Out NAS Storage architectures. Unlike traditional setups, these architectures distribute data and metadata across multiple independent nodes working in parallel.
While this distributed approach provides near-linear performance and capacity scaling, it introduces significant complexity regarding data consistency. When multiple clients access and modify the same files simultaneously across different physical nodes, the system must ensure that every client reads the most up-to-date version of the data. If one node caches a file and modifies it, other nodes holding the same file in their local cache must be immediately notified to invalidate or update their stale copies. This synchronization process is known as cache coherency.
Understanding how Scale Out NAS Storage maintains this coherency is critical for storage architects and system administrators who rely on high-performance infrastructure to support mission-critical workloads.
The Architecture of Distributed Caching
In advanced NAS Systems, each storage node typically features its own local cache, consisting of high-speed RAM and NVMe solid-state drives. This local cache serves to accelerate read and write operations by acknowledging client requests before the data is committed to slower, persistent backing storage.
When a client requests a file, the node processing the request checks its local cache. If the data is present (a cache hit), the node serves it immediately. If not (a cache miss), the node retrieves the data from the persistent storage pool, caches it locally, and then serves it to the client. This model works flawlessly for isolated access. However, when multiple nodes attempt to cache and modify the same data blocks concurrently, the system requires a robust arbitration mechanism.
Mechanisms for Maintaining Cache Coherency
To prevent data corruption and ensure strict consistency, Scale Out NAS Storage relies on sophisticated protocols that manage how and when data can be cached, read, and written across the cluster.
Distributed Lock Managers (DLM)
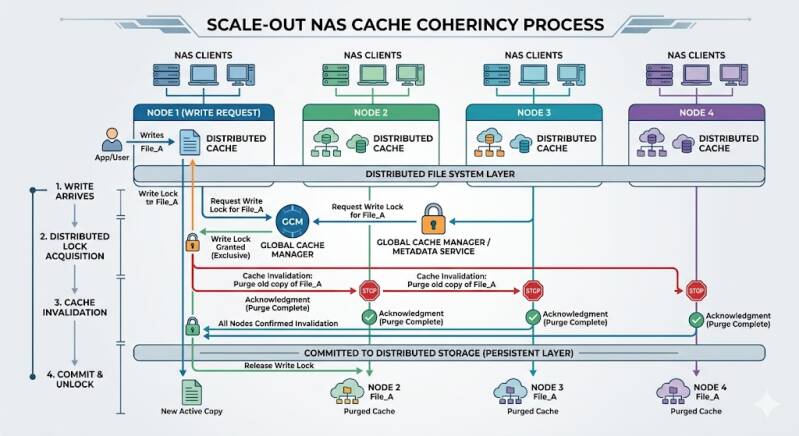
The most common method for managing concurrent access in NAS Systems is the implementation of a Distributed Lock Manager (DLM). A DLM operates as a cluster-wide traffic controller for file and byte-range locks. Before a node can modify a file, it must request a write lock from the DLM.
Once the lock is granted, the DLM broadcasts a message to all other nodes in the cluster, instructing them to invalidate any cached copies of that specific file or byte range. Until the modifying node completes its write operation and releases the lock, other nodes attempting to read or write to that file are queued or served directly from the node holding the exclusive lock. This guarantees that no two nodes can create conflicting versions of the same file.
Directory-Based Coherency Protocols
For highly parallel workloads, broadcasting invalidation messages to every node in a massive cluster consumes excessive network bandwidth and introduces unacceptable latency. To solve this, enterprise Scale Out NAS Storage implementations often utilize directory-based cache coherency protocols.
In a directory-based system, a centralized or distributed directory keeps a record of which nodes currently hold a copy of a specific memory block or file in their cache. When a node requests to modify a file, the system consults the directory and sends targeted invalidation messages only to the specific nodes known to possess a cached copy of that file. This drastically reduces interconnect traffic and allows the cluster to scale to hundreds of nodes without succumbing to coherency overhead.
The MESI Protocol Adaptation
Many distributed storage systems adapt variations of the MESI (Modified, Exclusive, Shared, Invalid) protocol, originally designed for CPU cache coherency, to manage node-level caching.
- Modified: The node has modified the data in its cache, and this data has not yet been written back to the shared storage. No other node has this data cached.
- Exclusive: The node has a clean copy of the data, and no other node has it cached. The node can transition this to 'Modified' without querying the cluster.
- Shared: Multiple nodes hold clean copies of the data for read-only access.
- Invalid: The cached data is stale and cannot be used.
By tracking these states, the storage operating system can intelligently manage read and write requests without constantly locking the entire file system.
Network Protocols and Interconnects
The efficiency of cache coherency operations heavily depends on the underlying network infrastructure. In traditional NAS Systems, metadata operations and lock requests can become bottlenecked by standard TCP/IP network latency.
To overcome this, modern distributed architectures utilize high-speed, low-latency back-end interconnects such as InfiniBand or 100/400 Gigabit Ethernet. Furthermore, they leverage Remote Direct Memory Access (RDMA). RDMA allows one storage node to read from or write to the memory (cache) of another storage node directly, bypassing the operating system kernel and CPU overhead. When a node needs to fetch the latest modified data from a peer node's cache, RDMA enables this transfer in microseconds, making the cache coherency process nearly invisible to the end-user applications.
Client-facing protocols also play a role. NFSv4 (Network File System version 4) and SMB3 (Server Message Block version 3) include advanced features like delegations and opportunistic locks (oplocks). These protocol-level mechanisms allow the server to grant a client exclusive caching rights temporarily, pulling the coherency boundary all the way down to the client workstation until another client requests access to the same file.
Ensuring Data Integrity for the Future
As machine learning, high-performance computing, and massive media rendering workflows continue to demand higher throughput, the algorithms governing distributed caching must become even more efficient. By utilizing Distributed Lock Managers, directory-based tracking, and RDMA interconnects, modern Scale Out NAS Storage successfully bridges the gap between high-speed local caching and cluster-wide data consistency.
Organizations deploying these advanced NAS Systems must carefully evaluate their interconnect networking and metadata architecture. Selecting a solution with a robust, low-latency cache coherency implementation is the only way to guarantee both data integrity and uncompromised performance at scale.
Add comment
Comments