As enterprises generate unprecedented volumes of data, traditional storage architectures struggle to maintain performance and capacity. IT departments increasingly adopt scale out storage to manage this exponential growth. However, distributing data across multiple independent nodes introduces significant technical challenges, primarily regarding data consistency and resource management. When multiple clients attempt to read or write the same file simultaneously across different hardware, the system must ensure data integrity without degrading performance.
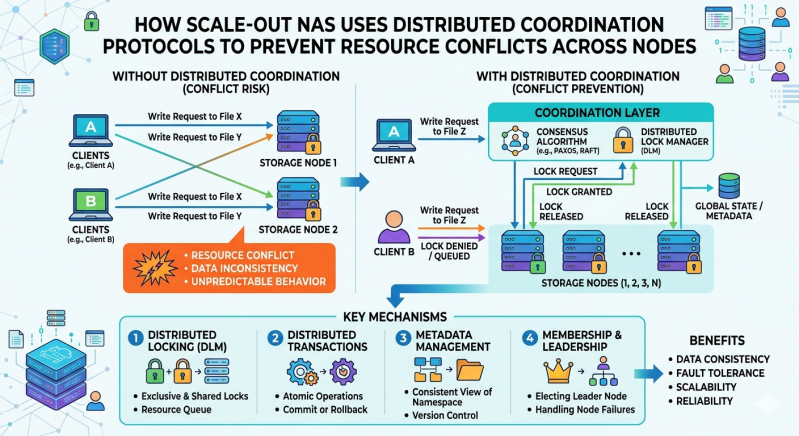
Scale out NAS addresses these concurrent access challenges through the implementation of distributed coordination protocols. These protocols act as the authoritative control mechanism within modern network storage solutions, synchronizing state and managing permissions across all connected nodes. Without strict coordination, independent nodes might overwrite each other's data, leading to permanent corruption and catastrophic system failure.
This article examines the underlying mechanisms behind distributed coordination. You will understand how consensus protocols function within a scale out NAS environment to maintain strict data consistency. By exploring distributed locking and quorum algorithms, storage administrators can better evaluate and optimize their network storage solutions for high availability, fault tolerance, and absolute data integrity.
The Architecture of Scale Out Storage
Unlike traditional scale-up storage, which relies on adding drives to a single controller, scale out storage expands by adding entire nodes. Each node contains its own processing power, memory, and storage capacity. These nodes are clustered together over a high-speed network to form a single, unified namespace. This architecture allows organizations to scale capacity and performance linearly by simply attaching new hardware to the cluster.
While this decentralized architecture provides massive scalability, it creates a complex environment for data management. Because any node in a scale out NAS cluster can service client requests, multiple nodes might receive instructions to modify the exact same file simultaneously. The file system must provide POSIX-compliant file semantics, meaning that if one client opens a file for writing, other clients must be restricted or properly sequenced to prevent data corruption.
Managing this state across a network introduces latency and the potential for network partitions. A reliable mechanism is required to ensure that all nodes agree on the current state of every file, lock, and directory structure at any given millisecond.
Distributed Coordination Protocols Explained
To maintain order and prevent conflicts, scale out NAS relies on distributed coordination protocols. These are mathematical algorithms designed to help a network of independent computers agree on a single source of truth, even in the presence of hardware failures or network interruptions. The most widely implemented protocols in modern network storage solutions are Paxos and Raft.
These protocols operate on the principle of distributed consensus. Instead of relying on a single master node—which would create a dangerous single point of failure—the cluster nodes communicate constantly to elect leaders and agree on state changes. When a client initiates a write request to a scale out NAS, the receiving node proposes the change to the rest of the cluster. The change is only committed when a majority of the nodes acknowledge and record the proposal.
By utilizing consensus protocols, scale out storage systems ensure that every node maintains a synchronized view of the file system's metadata. If a node fails or disconnects, the rest of the cluster continues to operate securely, knowing that the distributed state remains accurate and consistent.
Preventing Resource Conflicts Across Nodes
The theoretical foundation of consensus protocols translates into practical mechanisms that actively prevent resource conflicts. Network storage solutions implement these mechanisms at the file system level to control access dynamically.
Distributed Lock Management
The primary tool for conflict resolution in a scale out NAS is the Distributed Lock Manager (DLM). When a client requests write access to a file, the node servicing that client must obtain a lock from the DLM. The DLM uses the underlying coordination protocol to check if any other node currently holds a lock on that specific file or byte-range.
If the file is unlocked, the DLM grants exclusive access to the requesting node. The consensus protocol ensures that every other node in the cluster instantly registers this lock. If another client attempts to write to the same file via a different node, that node will check the DLM, see the active lock, and queue the request until the first operation completes. This systematic locking mechanism prevents overlapping writes and maintains strict data integrity.
Quorum and Split-Brain Prevention
Another critical function of distributed coordination is maintaining quorum. In a scale out storage cluster, a network failure might accidentally sever the communication between two halves of the cluster. Without coordination, both halves might assume the other has failed and attempt to take control of the storage backend. This scenario, known as "split-brain," leads to severe data corruption as both factions write conflicting data.
Coordination protocols prevent split-brain by requiring a strict majority, or quorum, to authorize any state changes. If a five-node scale out NAS cluster splits into a group of three and a group of two, the group of three retains quorum and continues processing data. The group of two, recognizing it lacks a majority, will automatically halt client access to prevent conflicts. This mathematical certainty makes network storage solutions highly resilient against unpredictable network infrastructure failures.
Why Network Storage Solutions Rely on Strict Coordination?
Data consistency is the most critical metric for any enterprise storage architecture. High performance and massive capacity are irrelevant if the underlying data becomes corrupted due to uncoordinated concurrent access. Implementing robust distributed coordination protocols requires significant engineering and processing overhead, but it is an absolute necessity for enterprise reliability.
Modern scale out storage must support highly transactional workloads, virtualized environments, and massive databases. These applications require exact precision and strict adherence to file locking standards. By leveraging protocols like Raft or Paxos, scale out NAS providers guarantee that their systems can handle millions of concurrent operations across dozens of nodes without a single overlapping write.
Furthermore, these protocols enable non-disruptive upgrades and seamless hardware replacements. Because the state is continuously coordinated across the cluster, administrators can remove or add nodes dynamically. The coordination protocol simply recalculates the quorum and redistributes the lock management responsibilities, ensuring zero downtime for the end users.
Strategic Next Steps for Storage Infrastructure
Understanding the mechanics of distributed coordination provides IT leaders with the necessary context to evaluate infrastructure upgrades. When reviewing modern scale out NAS offerings, organizations must inquire about the specific locking mechanisms and consensus algorithms powering the backend.
Evaluate your current network storage solutions to determine if they provide true distributed consensus or if they rely on vulnerable single-node metadata controllers. As your data footprint expands, prioritize architectures that utilize mathematically proven coordination protocols to protect your most valuable digital assets against concurrent access conflicts.
Add comment
Comments