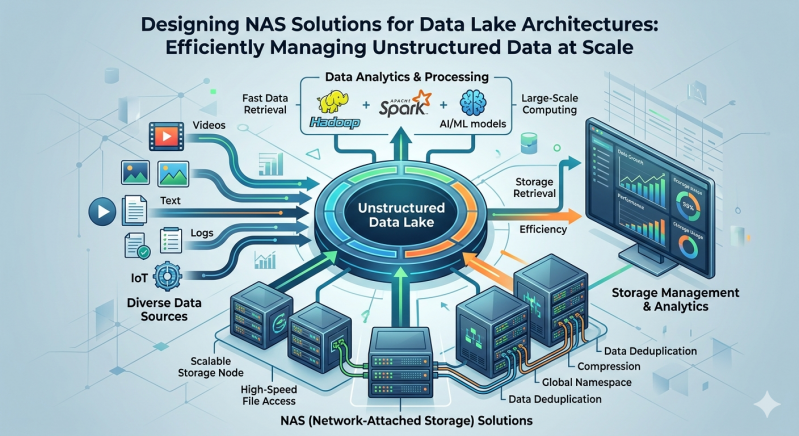
Enterprise organizations face a continuous influx of unstructured data. Audio files, video streams, application logs, and IoT sensor outputs require robust, highly available repositories. Data lakes serve as centralized storage repositories that allow you to store massive amounts of raw data in its native format. This architecture supports enterprise-level analytics and machine learning workloads by breaking down traditional data silos.
Hardware and software infrastructure must deliver exceptional performance, high availability, and massive scalability to support these data lakes. Network Attached Storage (NAS) provides a highly effective methodology for handling this requirement. Properly architecting storage networks ensures that compute nodes can ingest, process, and analyze data without encountering debilitating I/O bottlenecks.
Designing effective NAS solutions forms the critical foundation of a modern data strategy. By deploying optimized NAS systems, IT architects can guarantee that unstructured data remains highly accessible, secure, and ready for advanced computational analysis. This guide explores the foundational principles and technical requirements for integrating NAS infrastructure into large-scale data lake environments.
The Architectural Shift to Scale-Out NAS
Traditional storage networks often rely on scale-up architectures. Administrators add disk shelves to a single storage controller until it reaches its maximum capacity or performance limit. Once the controller maxes out, the entire system becomes a bottleneck, forcing a costly forklift upgrade or the creation of isolated storage silos.
Data lakes demand a different approach. Scale-out NAS solutions solve the limitations of traditional models by clustering multiple storage nodes together. As you add nodes to the cluster, you increase storage capacity and aggregate computing power and network bandwidth. This linear scaling model aligns perfectly with the unpredictable growth patterns of unstructured data.
Scale-out NAS systems distribute data and metadata across all available nodes. When an analytics application requests a massive dataset, multiple nodes work in parallel to deliver the information. This parallel processing capability drastically reduces latency and improves overall throughput for read-heavy analytics workloads.
Key Considerations for Enterprise NAS Systems
Architecting storage for a data lake requires careful evaluation of several technical parameters. Storage administrators must balance performance, capacity, and cost while maintaining strict security postures.
Protocol Support and Interoperability
Data lakes ingest information from a wide variety of sources. Your NAS infrastructure must support multiple file-sharing protocols concurrently. Network File System (NFS) and Server Message Block (SMB) remain the standard protocols for enterprise file sharing. However, modern data lakes also require object storage capabilities.
Top-tier NAS solutions provide native multiprotocol support, allowing users to access the same dataset via NFS, SMB, or Amazon S3 APIs. This interoperability eliminates the need to copy or migrate data between different storage tiers, saving time and reducing storage overhead.
Performance Tiering and NVMe Integration
Not all data holds the same immediate value. Hot data requires high-speed access for real-time analytics, while cold data can reside on slower, more cost-effective media. Modern NAS systems incorporate automated storage tiering to manage this lifecycle seamlessly.
High-performance tiers utilize Non-Volatile Memory Express (NVMe) solid-state drives. NVMe bypasses the legacy SAS/SATA controllers, connecting directly to the PCIe bus to deliver extreme IOPS and microsecond latency. As data cools, the NAS software automatically migrates it to high-capacity spinning disks or public cloud storage, optimizing the overall cost per gigabyte.
Data Protection and Fault Tolerance
Unstructured data often represents a company's most valuable intellectual property. Protecting this data against hardware failures and ransomware attacks is paramount. Scale-out NAS architectures utilize advanced erasure coding instead of traditional RAID configurations.
Erasure coding breaks data into fragments, expands it with redundant data pieces, and stores it across different nodes. If a drive or an entire node fails, the system can rebuild the missing data using the surviving fragments. This method provides higher fault tolerance and faster rebuild times than RAID, which is crucial when managing multi-petabyte storage environments.
Furthermore, administrators must implement immutable snapshots. These read-only copies of the file system protect against malicious encryption by providing an unalterable recovery point in the event of a ransomware breach.
Managing Metadata at Scale
Unstructured data is notoriously difficult to index and search. Without proper categorization, a data lake quickly deteriorates into an unmanageable data swamp. NAS solutions manage this complexity through advanced metadata handling.
Metadata provides the context—such as creation date, author, file type, and custom tags—that makes unstructured data searchable. Enterprise NAS systems utilize distributed metadata architectures to prevent bottlenecks during heavy file creation or search operations. By isolating metadata operations from actual data read/write paths, the storage cluster maintains high performance even when processing billions of small files.
Administrators can leverage this metadata to automate data governance policies. The storage system can automatically archive files that haven't been accessed in a year, or encrypt files containing personally identifiable information (PII) based on predefined metadata triggers.
Future-Proofing Your Unstructured Data Strategy
The volume and velocity of enterprise data will only continue to accelerate. Building a robust data lake requires storage infrastructure capable of adapting to future analytical demands.
By implementing scale-out NAS solutions with automated tiering, multiprotocol support, and advanced erasure coding, organizations can efficiently manage unstructured data at any scale. Carefully evaluate your current I/O requirements and projected growth rates. Partner with hardware vendors that provide transparent scaling mechanisms and robust metadata management tools. Investing in the right NAS systems today ensures your data lake remains a powerful engine for business intelligence and innovation for years to come.
Add comment
Comments